A07 | Spatio-temporal Models of Human Attention for Optimization of Information Visualizations


Despite the importance of human vision for perceiving and understanding information visualizations, dominant approaches to quantify users’ visual attention require special-purpose eye tracking equipment. However, such equipment is not always available, has to be calibrated to each user, and is limited to post-hoc optimization of information visualizations.
This project aims to integrate automatic quantification of spatio-temporal visual attention directly into the visualization design process without the need for any eye tracking equipment. To achieve these goals, the project takes inspiration from computational models of visual attention (saliency models) that mimic basic perceptual processing to reproduce attentive behavior. Originally introduced in computational neuroscience, saliency models have been tremendously successful in several research fields, particularly in computer vision. In contrast, few works have investigated the use of saliency models in information visualization. We will develop new methods for data-driven attention prediction for information visualizations as well as joint modeling of bottom-up and top-down visual attention, and use them to investigate attention-driven optimization and real-time adaptation of static and dynamic information visualizations.
Research Questions
How can we predict attention on a wide range of real-world information visualizations?
Which optimisation goals and mechanisms are required to optimise static information visualisations?
How can we jointly model bottom-up and top-down attention on dynamic information visualisations?
Which mechanisms are required to adapt visual analytics interfaces to users' attention?
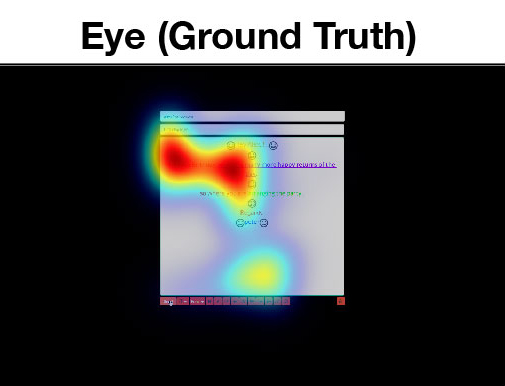
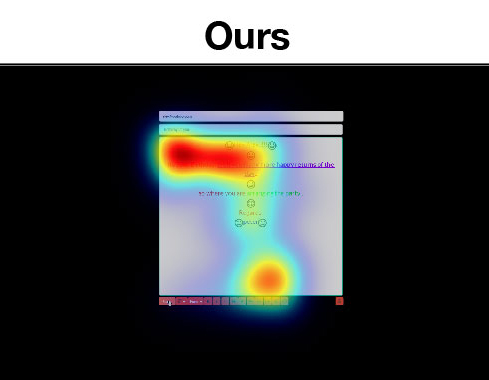
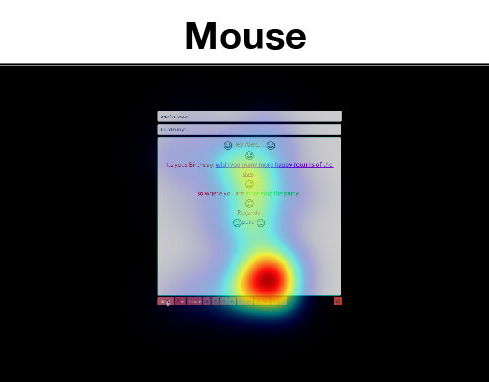
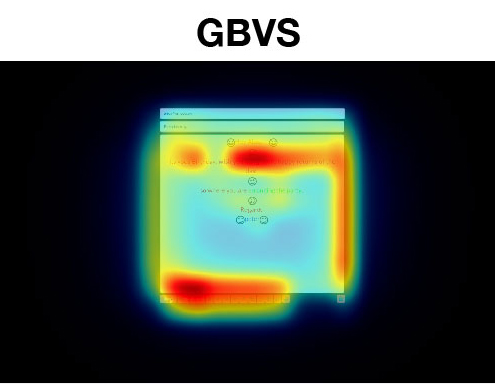
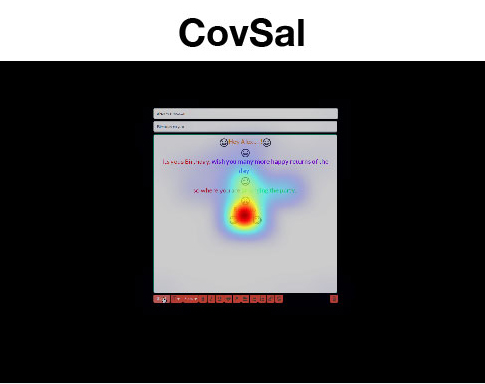
Sample Attention Maps
Sample attention maps from different models compared to the ground truth obtained using an eye tracker.
Our maps closely match the ground truth while existing approaches fail to incorporate important user interace areas.



Publications
- V. Oei et al., “RobustSpring: Benchmarking Robustness to Image Corruptions for Optical Flow, Scene Flow and Stereo,” in 14th International Conference on Learning Representations (ICLR 2026), Apr. 2026.
- Y. Wang, J. Nagasawa, D. Shi, C. Jiao, Y. Jiang, and A. Bulling, “Is this it? Benchmarking Scanpath Metrics for Information Display,” in Proceedings of the Symposium on Eye Tracking Research & Applications (ETRA), ACM, Jun. 2026, pp. 1–7. doi: 10.1145/3797246.3805691.
- D. Shi, Y. Wang, Y. Bai, A. Bulling, and A. Oulasvirta, “Chartist: Task-driven Eye Movement Control for Chart Reading,” in Proceedings of the CHI Conference on Human Factors in Computing Systems, New York, NY, United States, May 2025, pp. 1–14. doi: 10.1145/3706598.3713128.
- Z. Wu, Y. Wang, M. Langer, and A. M. Feit, “RelEYEance: Gaze-based Assessment of Users’ AI-reliance at Run-time,” in Proceedings of the ACM on Human-Computer Interaction, ACM, Ed., May 2025, pp. 1–18. doi: 10.1145/3725841.
- L. Zhang et al., “Towards a Better Understanding of Graph Perception in Immersive Environments,” in 33rd International Symposium on Graph Drawing and Network Visualization (GD 2025), 2025, pp. 1–19. doi: 10.4230/LIPIcs.GD.2025.9.
- M. Chang, Y. Wang, H. W. Wang, A. Bulling, and C. X. Bearfield, “Grid Labeling: Crowdsourcing Task-Specific Importance from Visualizations,” in Proceedings of the Eurographics Conference on Visualization (EuroVis), ACM, Ed., Jun. 2025, pp. 1–6. doi: 10.1145/3715669.3725883.
- M. Chang, Y. Wang, H. W. Wang, Y. Zhou, A. Bulling, and C. X. Bearfield, “Tell Me Without Telling Me: Two-Way Prediction of Visualization Literacy and Visual Attention,” in Proceedings of the IEEE Visualization Conference (VIS), Institute of Electrical and Electronics Engineers (IEEE), 2025, pp. 1–11. doi: 10.1109/tvcg.2025.3634815.
- C. Jiao, Y. Wang, G. Zhang, M. Bâce, Z. Hu, and A. Bulling, “DiffGaze: A Diffusion Model for Modelling Fine-grained Human Gaze Behaviour on 360° Images,” ACM Transactions on Interactive Intelligent Systems, pp. 1–22, 2025, doi: 10.1145/3772075.
- M. Sönnichsen, M. Elfares, Y. Wang, R. Küsters, A. Roitberg, and A. Bulling, “AttentionLeak: What Does Human Attention Reveal About Information Visualisation?,” in International Conference on Document Analysis and Recognition, Cham: Springer Nature Switzerland, Sep. 2025, pp. 1–11. doi: 10.1007/978-3-032-04627-7_5.
- T. Nishiyasu, T. Kostorz, Y. Wang, Y. Sato, and A. Bulling, “ChartQC: Question Classification from Human Attention Data on Charts,” in Proceedings of the Symposium on Eye Tracking Research & Applications (ETRA), May 2025, pp. 1–6. doi: 10.1145/3715669.3725883.
- Y. Wang, Y. Jiang, Z. Hu, C. Ruhdorfer, M. Bâce, and A. Bulling, “VisRecall++: Analysing and Predicting Visualisation Recallability from Gaze Behaviour,” Proc. ACM on Human-Computer Interaction (PACM HCI), vol. 8, pp. 1–18, Jul. 2024, doi: 10.1145/3655613.
- Y. Wang et al., “SalChartQA: Question-driven Saliency on Information Visualisations,” in Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI), ACM, May 2024, pp. 1–14. doi: 10.1145/3613904.3642942.
- Y. Wang, Q. Dai, M. Bâce, K. Klein, and A. Bulling, “Saliency3D: a 3D Saliency Dataset Collected on Screen,” in Proc. ACM International Symposium on Eye Tracking Research and Applications (ETRA), ACM, 2024, pp. 1–6. doi: 10.1145/3649902.3653350.
- E. Sood, L. Shi, M. Bortoletto, Y. Wang, P. Müller, and A. Bulling, “Improving Neural Saliency Prediction with a Cognitive Model of Human Visual Attention,” in Proceedings of the 45th Annual Meeting of the Cognitive Science Society (CogSci), Jul. 2023, pp. 3639–3646. [Online]. Available: https://escholarship.org/uc/item/5968p71m
- Y. Wang, M. Bâce, and A. Bulling, “Scanpath Prediction on Information Visualisations,” IEEE Transactions on Visualization and Computer Graphics, pp. 1–15, Feb. 2023, doi: 10.1109/TVCG.2023.3242293.
- F. Chiossi et al., “Adapting visualizations and interfaces to the user,” it - Information Technology, vol. 64, pp. 133–143, 2022, doi: 10.1515/itit-2022-0035.
- Y. Wang, C. Jiao, M. Bâce, and A. Bulling, “VisRecall: Quantifying Information Visualisation Recallability Via Question Answering,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, Art. no. 12, 2022, [Online]. Available: https://ieeexplore.ieee.org/document/9855227
- Y. Wang, M. Koch, M. Bâce, D. Weiskopf, and A. Bulling, “Impact of Gaze Uncertainty on AOIs in Information Visualisations,” in 2022 Symposium on Eye Tracking Research and Applications, ACM, Jun. 2022, pp. 1–6. doi: 10.1145/3517031.3531166.
- K. Kurzhals et al., “Visual Analytics and Annotation of Pervasive Eye Tracking Video,” in Proceedings of the Symposium on Eye Tracking Research & Applications (ETRA), ACM, 2020, pp. 16:1–16:9. doi: 10.1145/3379155.3391326.
- H. Sattar, A. Bulling, and M. Fritz, “Predicting the Category and Attributes of Visual Search Targets Using Deep Gaze Pooling,” in Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), 2017, pp. 2740–2748. [Online]. Available: https://ieeexplore.ieee.org/document/8265534
- M. Tonsen, J. Steil, Y. Sugano, and A. Bulling, “InvisibleEye: Mobile Eye Tracking Using Multiple Low-Resolution Cameras and Learning-Based Gaze Estimation,” in Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT), 2017, pp. 106:1–106:21. doi: 10.1145/3130971.
- X. Zhang, Y. Sugano, M. Fritz, and A. Bulling, “MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, Art. no. 1, 2017, [Online]. Available: https://ieeexplore.ieee.org/abstract/document/8122058
- X. Zhang, Y. Sugano, and A. Bulling, “Everyday Eye Contact Detection Using Unsupervised Gaze Target Discovery,” in Proceedings of the ACM Symposium on User Interface Software and Technology (UIST), 2017, pp. 193–203. doi: 10.1145/3126594.3126614.
- E. Wood, T. Baltrusaitis, L.-P. Morency, P. Robinson, and A. Bulling, “A 3D Morphable Eye Region Model for Gaze Estimation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2016, pp. 297–313. [Online]. Available: https://link.springer.com/chapter/10.1007%2F978-3-319-46448-0_18
- P. Xu, Y. Sugano, and A. Bulling, “Spatio-Temporal Modeling and Prediction of Visual Attention in Graphical User Interfaces,” in Proceedings of the CHI Conference on Human Factors in Computing Systems, 2016, pp. 3299–3310.
- E. Wood, T. Baltrusaitis, L.-P. Morency, P. Robinson, and A. Bulling, “Learning an Appearance-Based Gaze Estimator from One Million Synthesised Images,” in Proceedings of the Symposium on Eye Tracking Research & Applications (ETRA), 2016, pp. 131–138. doi: 10.1145/2857491.2857492.
- X. Zhang, Y. Sugano, M. Fritz, and A. Bulling, “It’s Written All Over Your Face: Full-Face Appearance-Based Gaze Estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2299–2308. [Online]. Available: https://ieeexplore.ieee.org/document/8015018
Project Group A
Models and Measures
Completed
Project Group B
Adaptive Algorithms
Completed
Project Group C
Interaction
Completed
Project Group D
Applications
Completed

FOR SCIENTISTS
Projects
People
Publications
Graduate School
Equal Opportunity
FOR PUPILS
PRESS AND MEDIA
SOCIAL MEDIA





© SFB-TRR 161 | Quantitative Methods for Visual Computing | 2019.